

SQL is the backbone of modern data management, enabling organizations to store and process massive amounts of information easily and efficiently. As a powerful and versatile language, SQL performs a wide range of database operations, including creating tables, inserting and updating data, and retrieving information from large datasets. With its ability to enforce data integrity and relationships between tables, as well as perform complex data analysis and manipulation, it is no wonder that SQL has become an essential tool in data analytics. Whether you are a database administrator, a data analyst, or a software developer, understanding the basics of SQL is critical to your success. In this conclusion, we will delve into the various components of SQL, including commands, joins, keys, constraints, and more, to give you a comprehensive understanding of this essential language.
What is SQL?
SQL (Structured Query Language) is a standard programming language for managing and manipulating relational databases. It is used to insert, update, delete, and retrieve data from databases.
SQL is widely used for data analysis and management in various applications and industries, from financial systems, e-commerce websites, and government agencies to small businesses and individual users. The language consists of a set of commands and statements that perform specific tasks, such as creating tables, querying data, and modifying records.
SQL is a relational database management system that uses a relational model to organize data into tables comprising rows and columns. This allows for easy querying and analysis of data and provides a way to structure data in a flexible and efficient way.
What is a database management system?
A database management system (DBMS) is a software system designed to manage and organize data stored in a database. A database is a collection of data organized in a specific way, allowing for efficient storage, retrieval, and manipulation of data. The DBMS acts as the intermediary between the database and the user, providing tools and interfaces for storing, organizing, and retrieving data in a database.
The main functions of a DBMS include the following:
- Data definition: The DBMS provides a way to define the structure of the database, including the names and types of fields and the relationships between tables.
- Data storage: The DBMS is responsible for storing the data in the database in an efficient and organized manner.
- Data retrieval: The DBMS provides a way for users to retrieve data from the database, either by executing structured queries or through more flexible search and retrieval interfaces.
- Data manipulation: The DBMS provides a way to manipulate the data in the database, including inserting, updating, and deleting records.
- Data security: The DBMS provides a way to control the database’s access and protect the data from unauthorized access or modification.
- Data backup and recovery: The DBMS provides a way to back up and recover the database in the event of a failure or data loss.
You may also like to read: Database Management System (DBMS) – Its Features & Types
Types of DBMS With Examples
There are several database management systems, each with its own features, strengths, and weaknesses. Some of the most common types include:
- Relational Database Management System (RDBMS): RDBMS is the most commonly used database management system. It uses a relational model to store data in tables, with rows and columns. Examples of RDBMS include Oracle, Microsoft SQL Server, MySQL, and PostgreSQL.
- Object-Relational Database Management System (ORDBMS): ORDBMS combines the features of both relational databases and object-oriented programming languages. It allows data to be stored as objects rather than just in tables. Examples of ORDBMS include PostgreSQL, MySQL, and Oracle.
- Hierarchical Database Management System (HDBMS): HDBMS is an older database management system that uses a hierarchical model to store data. This model organizes data in a tree-like structure, with each parent node having one or more child nodes. Examples of HDBMS include IBM’s Information Management System (IMS).
- Network Database Management System (NDBMS): NDBMS uses a network model to store data. This model is similar to the hierarchical model but allows for many-to-many relationships between records. Examples of NDBMS include Integrated Data Store (IDS).
- Document Database Management System (DDBMS): DDBMS stores data as documents rather than tables. Each document can contain multiple fields and can be easily retrieved and updated. Examples of DDBMS include MongoDB, CouchDB, and RavenDB.
- Column-Oriented Database Management System (CODBMS): Its stores data by columns rather than by rows. This makes it well suited for data warehousing and analytics, as it allows for fast retrieval of specific columns of data. Examples of CODBMS include Apache Cassandra and Google Bigtable.
- Key-Value Store Database Management System (KVSDBMS): KVSDBMS uses a simple key-value pair to store data. Each key is associated with a specific value, and data can be quickly retrieved by searching for a specific key. Examples of KVSDBMS include Redis and Amazon DynamoDB.
Types of SQL commands
SQL has several commands that perform various tasks, including data definition, data manipulation, and data control. Some of the most common types of SQL commands include:
- Data Definition Language (DDL)
- Data Manipulation Language (DML)
- Data Control Language (DCL)
- Transaction Control Language (TCL)
- Data Query Language (DQL)
You may also like to read: List of SQL Commands – A Beginner’s Guide To SQL
Data Definition Language (DDL)
DDL commands are used to define the structure of a database, including creating, altering, and dropping tables, as well as other database objects such as indexes and views. Examples of DDL commands include CREATE TABLE, ALTER TABLE, and DROP TABLE.
Here are some common DDL commands with examples:
CREATE TABLE
This command is used to create a new table in a database. The SQL syntax for creating a table is as follows:
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
.....
);For example, to create a table called “employees” with columns for name, age, and salary, the SQL query would look like this:
CREATE TABLE employees (
name varchar(50),
age int,
salary float
);ALTER TABLE:
This command is used to modify an existing table in a database. The SQL syntax for altering a table is as follows:
ALTER TABLE table_name action;Where “action” can be one of the following:
- ADD COLUMN: This action is used to add a new column to an existing table. For example:
ALTER TABLE employees ADD COLUMN email varchar(50);- DROP COLUMN: This action is used to remove a column from an existing table. For example:
ALTER TABLE employees DROP COLUMN age;- MODIFY COLUMN: This action is used to modify the data type or other properties of a column. For example:
ALTER TABLE employees MODIFY COLUMN salary decimal(10,2);DROP TABLE:
This command is used to delete a table from a database. The SQL syntax for dropping a table is as follows:
DROP TABLE table_name;For example, to delete the “employees” table, the SQL query would look like this:
DROP TABLE employees;CREATE INDEX:
This command is used to create an index on one or more columns of a table. Indexes are used to improve the performance of queries that search for data in a table. The SQL syntax for creating an index is as follows:
CREATE INDEX index_name ON table_name (column1, column2, ...);For example, to create an index called “idx_salary” on the “salary” column of the “employees” table, the SQL query would look like this:
CREATE INDEX idx_salary ON employees (salary);ALTER INDEX:
This command is used to modify an existing index in a database. The SQL syntax for altering an index is as follows:
ALTER INDEX index_name action;Where “action” can be one of the following:
- RENAME TO: This action is used to rename an index. For example:
ALTER INDEX idx_salary RENAME TO idx_employee_salary;DROP INDEX:
This command is used to delete an index from a database. The SQL syntax for dropping an index is as follows:
DROP INDEX index_name;For example, to delete the “idx_salary” index, the SQL query would look like this:
DROP INDEX idx_salary;Data Manipulation Language (DML)
DML commands are used to manipulate data stored in a database, including inserting, updating, and deleting records. Examples of DML commands include SELECT, INSERT, UPDATE, and DELETE.
Here are some common DML commands with examples:
INSERT
The INSERT command is used to add new rows to a table. The basic syntax for the INSERT command is as follows:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);For example, let’s say you have a table named customers with columns id, first_name, last_name, and email, and you want to add a new customer with the following information:
INSERT INTO customers (id, first_name, last_name, email)
VALUES (1, 'John', 'Doe', 'johndoe@example.com');UPDATE
The UPDATE command is used to modify existing rows in a table. The basic syntax for the UPDATE command is as follows:
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;For example, let’s say you want to update the email address of the customer with id 1 to “newemail@example.com”. You would use the following SQL query:
UPDATE customers
SET email = 'newemail@example.com'
WHERE id = 1;DELETE
The DELETE command is used to delete existing rows from a table. The basic syntax for the DELETE command is as follows:
DELETE FROM table_name
WHERE condition;For example, let’s say you want to delete the customer with id 1 from the customers table.
DELETE FROM customers
WHERE id = 1;SELECT
The SELECT command is used to retrieve data from a table. The basic syntax for the SELECT command is as follows:
SELECT column1, column2, ...
FROM table_name
WHERE condition;For example, let’s say you want to retrieve the first_name and last_name of all customers from the customers table
SELECT first_name, last_name
FROM customers;MERGE
MERGE is a SQL command used to perform both an INSERT and an UPDATE operation in a single statement. It is also known as UPSERT as it can insert a new row or update an existing one depending on whether a match is found. The basic syntax for the MERGE command is as follows:
MERGE INTO target_table AS T
USING source_table AS S
ON (T.join_column = S.join_column)
WHEN MATCHED THEN
UPDATE SET T.column1 = S.column1, T.column2 = S.column2, ...
WHEN NOT MATCHED THEN
INSERT (column1, column2, ...) VALUES (S.column1, S.column2, ...);For example, let’s say you have a customers table and you want to update or insert a new row based on the email address. If a customer with a matching email address already exists, you want to update their first_name and last_name
MERGE INTO customers AS T
USING (
SELECT 'johndoe@example.com' AS email, 'John' AS first_name, 'Doe' AS last_name
) AS S
ON (T.email = S.email)
WHEN MATCHED THEN
UPDATE SET T.first_name = S.first_name, T.last_name = S.last_name
WHEN NOT MATCHED THEN
INSERT (email, first_name, last_name) VALUES (S.email, S.first_name, S.last_name);Data Control Language (DCL)
DCL commands control access to a database, including granting and revoking privileges and creating and managing user accounts. Examples of DCL commands include GRANT and REVOKE.
GRANT
This command is used to provide privileges to a user or a group of users. The privileges can be granted on a table, view, or even the entire database. The syntax for the GRANT command is as follows:
GRANT privileges ON object TO user;For example, to grant the SELECT privilege on the customers table to the user johndoe, you would use the following GRANT query:
GRANT SELECT ON customers TO johndoe;REVOKE
This command is used to revoke the privileges that have been granted to a user or a group of users. The syntax for the REVOKE command is as follows:
REVOKE privileges ON object FROM user;For example, to revoke the SELECT privilege on the customers table from the user johndoe
REVOKE SELECT ON customers FROM johndoe;Transaction Control Language (TCL)
TCL commands are used to manage transactions, a series of related operations executed as a single unit of work. Examples of TCL commands include COMMIT and ROLLBACK.
COMMIT
This command is used to permanently save changes made during a transaction to the database. The syntax for the COMMIT command is as follows:
COMMIT;For example, if you have made changes to the customers table as part of a transaction and you want to save those changes to the database, you would use the following COMMIT query:
BEGIN TRANSACTION; INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (1, 'John', 'Doe', '2020-01-01', 50000);
COMMIT;ROLLBACK
This command is used to undo changes made during a transaction and restore the database to its previous state. The syntax for the ROLLBACK command is as follows:
ROLLBACK; For example, if you have made changes to the customers table as part of a transaction and you want to undo those changes and restore the database to its previous state, you would use the following ROLLBACK query:
BEGIN TRANSACTION; INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (1, 'John', 'Doe', '2020-01-01', 50000);
ROLLBACK; SAVEPOINT
The SAVEPOINT statement is used to create a savepoint within a transaction, allowing you to roll back to a specific point within the transaction instead of rolling back all changes. The syntax for creating a savepoint is as follows:
SAVEPOINT savepoint_name;For example, if you have made changes to the customers table as part of a transaction and you want to create a savepoint before making further changes, you would use the following SAVEPOINT query:
BEGIN TRANSACTION; INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (1, 'John', 'Doe', '2020-01-01', 50000);
SAVEPOINT savepoint_1;
INSERT INTO employees (employee_id, first_name, last_name, hire_date, salary)
VALUES (2, 'Jane', 'Doe', '2020-01-02', 55000);
ROLLBACK TO savepoint_1;
COMMIT; Data Query Language (DQL)
DQL commands are used to retrieve data from a database, including queries based on specific criteria and sorting and grouping data. Examples of DQL commands include SELECT and ORDER BY.
Here are some common DQL commands with examples:
SELECT
The SELECT statement is used to retrieve data from one or more tables. The syntax for a basic SELECT statement is as follows:
SELECT column1, column2, ... columnN FROM table_name; For Example:
SELECT first_name, last_name, salary FROM employees; WHERE
The WHERE clause is used to filter data based on specific conditions. The syntax for a SELECT statement with a WHERE clause is as follows:
SELECT column1, column2, ... columnN
FROM table_name
WHERE condition; For Example:
SELECT first_name, last_name, salary
FROM employees
WHERE salary > 50000; GROUP BY
The GROUP BY clause is used to group data based on specific columns. The syntax for a SELECT statement with a GROUP BY clause is as follows:
SELECT column1, SUM(column2), AVG(column3), ...
FROM table_name
GROUP BY column1; For Example:
SELECT department,
AVG(salary)
FROM employees
GROUP BY department; HAVING
The HAVING clause is used to filter groups based on specific conditions. The syntax for a SELECT statement with a GROUP BY and HAVING clause is as follows:
SELECT column1, SUM(column2), AVG(column3), ...
FROM table_name
GROUP BY column1
HAVING condition; For Example:
SELECT department, AVG(salary)
FROM employees
GROUP BY department
HAVING AVG(salary) > 50000; JOIN
The JOIN clause is used to combine data from two or more tables based on a common column. The syntax for a SELECT statement with a JOIN clause is as follows:
SELECT column1, column2, ... columnN
FROM table1
JOIN table2
ON condition; For Example:
SELECT employees.first_name, employees.last_name, departments.name
FROM employees
JOIN departments
ON employees.department_id = departments.department_id; What are Joins in SQL?
In SQL, a join is a way to combine rows from two or more tables based on related columns between them. Joins are used to retrieve data from multiple tables in a single query, making it easier to get a complete picture of the data you are working with.
The most common type of join is the inner join, which returns only the rows with matching values in both tables. However, there are several other types of joins, including left, right, and full outer join.
Joins are based on the relationship between two or more tables, typically defined using a primary key and a foreign key. The primary key is a unique identifier for each row in the table, while the foreign key is a column in a table that refers to the primary key of another table.
Types of joins are in SQL
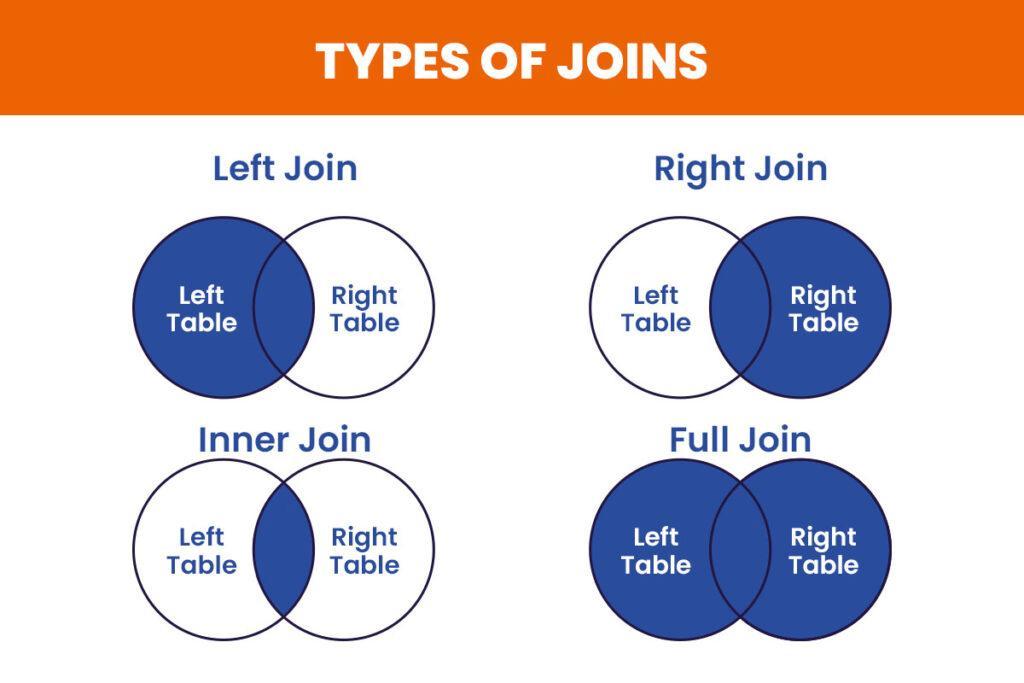
- INNER JOIN: The INNER JOIN clause returns only the rows that have matching values in both tables. It is the most commonly used join and the default join type.
SELECT column1, column2, ...
FROM table1
INNER JOIN table2
ON table1.column = table2.column; For Example:
SELECT employees.name, departments.name
FROM employees
INNER JOIN departments
ON employees.department_id = departments.id; - LEFT JOIN (or LEFT OUTER JOIN): The LEFT JOIN clause returns all the rows from the left table (table1), and the matching rows from the right table (table2). The result will contain non-matching rows from the right side, filled with NULL values.
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2
ON table1.column = table2.column; For Example:
SELECT employees.name, departments.name
FROM employees
LEFT JOIN departments
ON employees.department_id = departments.id; - RIGHT JOIN (or RIGHT OUTER JOIN): The RIGHT JOIN clause returns all the rows from the right table (table2), and the matching rows from the left table (table1). The result will contain non-matching rows from the left side, filled with NULL values.
SELECT column1, column2, ...
FROM table1
RIGHT JOIN table2
ON table1.column = table2.column; For Example:
SELECT employees.name, departments.name
FROM employees
RIGHT JOIN departments
ON employees.department_id = departments.id; - FULL OUTER JOIN: The FULL OUTER JOIN clause returns all the rows from both tables, including the matching and non-matching rows. The result will contain NULL values for non-matching rows from either side.
SELECT column1, column2, ...
FROM table1
FULL OUTER JOIN table2
ON table1.column = table2.column; For Example:
SELECT employees.name, departments.name
FROM employees
FULL OUTER JOIN departments
ON employees.department_id = departments.id;- CROSS JOIN: The CROSS JOIN clause returns the Cartesian product of the two tables, which means it returns every possible combination of rows from the two tables.
SELECT column1, column2, ...
FROM table1
CROSS JOIN table2; For Example:
SELECT employees.name, departments.name
FROM employees
CROSS JOIN departments; What are Keys in SQL?
In SQL, a “key” is a field or set of fields in a database table that are used to identify unique rows or records. Keys are important for maintaining the integrity and accuracy of the data in a database, as they prevent duplicate rows from being inserted and enable efficient data retrieval through indexing.
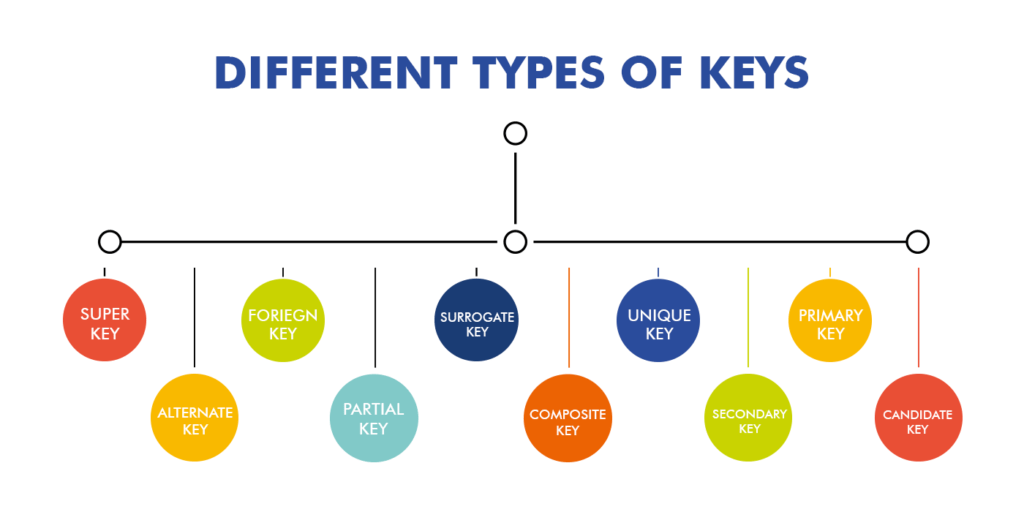
There are several types of keys in SQL, including:
- Primary Key: A primary key is a unique identifier for a row or record in a table. It is used to enforce data integrity and prevent duplicate rows from being inserted.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
salary DECIMAL(10, 2)
); 2. Foreign Key: A foreign key is a field in a table that refers to the primary key of another table. It is used to establish a relationship between two tables, and to ensure that data in the foreign key table is consistent with the data in the primary key table.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
salary DECIMAL(10, 2),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments (id)
); What are Constraints in SQL?
In SQL, a “constraint” is a rule or restriction that is applied to a table or one or more columns within a table to ensure data integrity and consistency. Constraints help to maintain the accuracy, completeness, and reliability of the data stored in a database by enforcing rules for data entry and modification.
There are several types of constraints in SQL, including:
- NOT NULL: This constraint ensures that a column cannot contain NULL values.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
salary DECIMAL(10, 2)
); - UNIQUE: This constraint ensures that a column contains unique values, so no two records can have the same value in that column.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
email VARCHAR(50) UNIQUE,
age INT,
salary DECIMAL(10, 2)
); - CHECK: This constraint allows you to specify a condition that must be met for a record to be inserted or updated.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT CHECK (age > 18),
salary DECIMAL(10, 2)
); - DEFAULT: This constraint sets a default value for a column, so if no value is specified when a record is inserted, the default value will be used.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT,
salary DECIMAL(10, 2) DEFAULT 0.00
); Relationship Between Tables in SQL
There are three types of relationships between tables in SQL:
One-to-One
A one-to-one relationship exists when one record in a table is related to only one record in another table, and vice versa.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
salary DECIMAL(10, 2)
);
CREATE TABLE tax_info (
id INT PRIMARY KEY,
employee_id INT,
tax_number VARCHAR(50),
FOREIGN KEY (employee_id) REFERENCES employees (id)
); In this example, the “employees” table has a primary key defined as “id”. The “tax_info” table has a foreign key “employee_id” that references the primary key “id” in the “employees” table, establishing a one-to-one relationship between the two tables.
One-to-Many
A one-to-many relationship exists when one record in a table can be related to multiple records in another table, but each record in the second table can be related to only one record in the first table.
CREATE TABLE departments (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
salary DECIMAL(10, 2),
department_id INT,
FOREIGN KEY (department_id) REFERENCES departments (id)
); In this example, the “departments” table has a primary key defined as “id”. The “employees” table has a foreign key “department_id” that references the primary key “id” in the “departments” table, establishing a one-to-many relationship between the two tables.
Many-to-Many
A many-to-many relationship exists when multiple records in a table can be related to multiple records in another table. This type of relationship requires a third table, often referred to as a junction or associative table, to manage the relationship between the two tables.
CREATE TABLE employees (
id INT PRIMARY KEY,
name VARCHAR(50),
age INT,
salary DECIMAL(10, 2)
);
CREATE TABLE projects (
id INT PRIMARY KEY,
name VARCHAR(50)
);
CREATE TABLE employee_projects (
id INT PRIMARY KEY,
employee_id INT,
project_id INT,
FOREIGN KEY (employee_id) REFERENCES employees (id),
FOREIGN KEY (project_id) REFERENCES projects (id) ); In this example, the “employees” and “projects” tables each have a primary key defined as “id”. The “employee_projects” table is the associative table that manages the many-to-many relationship between the two tables, with foreign keys “employee_id” and “project_id” referencing the primary keys “id” in the “employees” and “projects” tables, respectively.
what is the role & importance of SQL in data analytics?
SQL (Structured Query Language) plays a crucial role in data analytics as it provides a way to interact with and manipulate data stored in databases. It allows data analysts to retrieve, aggregate, and manipulate large amounts of data to perform analysis and gain insights into trends and patterns.
SQL is important in data analytics because:
- Structured Data: SQL is designed to work with structured data stored in relational databases, making it an ideal language for working with large, complex data sets that are commonly encountered in data analytics.
- Flexibility: SQL provides a flexible and powerful way to work with data, allowing data analysts to perform complex calculations, aggregate data, and perform data transformations.
- Performance: SQL is optimized for data retrieval and manipulation, making it fast and efficient for processing large amounts of data.
- Integration: SQL can easily integrate with other tools commonly used in data analytics, such as data visualization tools and machine learning frameworks, allowing data analysts to build end-to-end data analytics pipelines.
- Data Quality: SQL provides a way to enforce data constraints and relationships between data, ensuring that the data is clean and consistent, which is crucial for accurate data analysis.
You may also like to read: Advance Sql For Data Analytics
Conclusion
In conclusion, SQL (Structured Query Language) is a standard programming language used for managing and manipulating relational databases. SQL supports various types of commands such as Data Definition Language (DDL), Data Manipulation Language (DML), Data Control Language (DCL), Transaction Control Language (TCL), and Data Query Language (DQL) commands. These commands allow you to perform operations such as creating, altering, and deleting tables and their associated constraints, as well as inserting, updating, and retrieving data from tables.
SQL supports various types of joins, including inner join, left join, right join, and full outer join, which are used to combine data from multiple tables. Keys and constraints are important components of relational databases, and they are used to enforce data integrity and relationships between tables. SQL supports various types of keys, including primary keys, foreign keys, and unique keys, and various types of constraints, such as NOT NULL, CHECK, and DEFAULT constraints.
Additionally, SQL is an important tool in data analytics, as it allows you to extract, transform, and load (ETL) data from multiple sources, as well as perform various types of data analysis and manipulation.

Perfect resource for anyone even when they don’t have prior knowledge about it!
Someone reading about SQL for the first time can definitely refer to this, the blog is very descriptive with live examples and screenshots of the codes which enhances the understandibility of the blog. A must read if you are trying to know about SQL
Going through this blog, I got to know alot about SQL as a whole. Full credits to Brainalyst for being my motivation to take this up and start learning it. Hope you will be supporting me and others in this too.
Thankyou and please keep sharing more such informative ones!
This is very neatly explained in an easy to grasp manner! Amazing
Amazing experience with brainalyst as content is very enriching✨
Well conducted research and valuable insights
Well structured and easy to understand language that much such a hard topic a piece of cake