
Introduction
Machine Learning helps in recognizing patterns in a massive databases to find solutions for the issue independently. Put basically. It is an umbrella term for many techniques and tools that can assist computers in learning and adapting independently.
Contrary to traditional programming, which manually creates a program that uses input data and runs on a computer to produce the output, in ML or augmented analytics, the input data and work are given to an algorithm to make a program. It leads to powerful insights that can assist in predicting future outcomes.
ML algorithms do all that and more by using statistics to find patterns in massive amounts of data that encompass everything from images, numbers, words, etc. If it can store the data in digital form can feed it into a ML algorithm for solving specific problems.
In Machine Learning, a procedure analyzes the data for building and training models. ML is everywhere now; from Amazon product recommendations to self-driven cars, it has excellent value throughout. As per the latest research, the global machine-learning market is expected to grow by 43% by 2024. This revolution has reached the heights of the demand for ML professionals to a great extent.
Artificial Intelligence and ML jobs have observed a significant growth rate of up to 75% in the past four years, and the industry is constantly growing. A career in the Machine learning domain gives job satisfaction, excellent growth, insanely high salary, but it is a complicated and challenging process. This growth has brought a lot of challenges for ML. In this article, we are going to talk about the challenges of machine learning.
You may also like to read more about – Benefits & Challenges of Business Intelligence
Real-Time Challenges of Machine Learning Projects
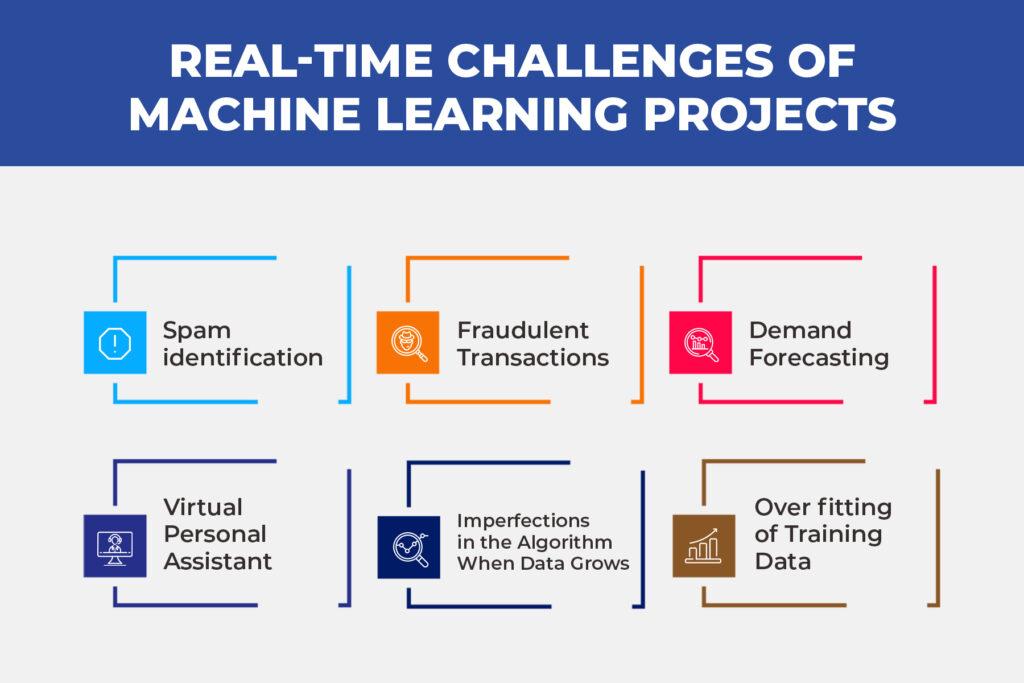
Spam identification
Spam identification is one of the most simple applications in machine learning. Most of our email inboxes also have an unsolicited volume or spam inbox, where the email provider automatically filters rejected spam emails.
How to know that the email is spam? The real challenge of the ML model is to identifying all spam emails based on standard features such as the email, subject, and sender content.
If you look at your email inbox carefully, you will realize that picking out spam emails is relatively easy as they look very contradicting from real emails. ML techniques used these days can automatically filter these spam emails in a very successful way.
Spam detection is one of the finest and most familiar problems solved by Machine Learning. Neural networks employ content-based filtering to classify unwanted emails as spam. These neural networks are related to the brain, which can identify spam emails and messages.
Fraudulent Transactions
Fraudulent banking is a challenge of machine learning in which transactions are familiar today. However, it is not achievable (in terms of cost involved and efficiency) to investigate each transaction for fraud, which translate to a poor customer service experience.
ML in finance can automatically make super-accurate prediction maintenance models for identifying and prioritizing all types of possible fraudulent activities. Businesses can then build a data-based queue and investigate high-priority incidents.
It enables you to deploy the resources in an area where you will see the greatest return on your investigative investment. Further, it also assists you in optimizing customer satisfaction to protect their accounts and not challenge valid transactions. Such fraud detection using machine learning can assist banks and financial organizations save money on conflict/charge backs as one can be trained in ML models for flagging transactions that appear fraudulent based on particular features.
Demand Forecasting
The concept of demand forecasting in the challenges of machine learning is assisted in various industries, from retail and e-commerce to manufacturing and transportation. It has historical data for Machine Learning algorithms and models to predict the number of products, services, power, and much more.
It enables businesses to effectively collect and process data from the whole supply chain, minimizing overheads and maximizing efficiency.
ML-powered demand to develop forecasts is very accurate, fast, and transparent. Businesses can be created as meaningful insights from a continuous supply/demand data stream and adapt to changes accordingly.
Virtual Personal Assistant
From Alexa and Google Assistant to Cortana and Siri, we have different virtual personal assistants for finding factual information using our voice instruction, such as calling someone, opening an email, scheduling an appointment, and more.
These virtual assistants use Machine Learning algorithms to record our voice instructions, send them over the server to a cloud, follow by decode them using Machine Learning algorithms and act accordingly.
Imperfections in the Algorithm When Data Grows
So you have found quality data and trained it amazingly, and the predictions are definite and accurate, which is one of the challenges of machine learning. Now you have learned how to make a machine learning algorithm. The model may become incompetent in the Future as data grows. The present best model may need to be revised in the future and require further rearrangement. It would help if you had constant monitoring and maintenance to keep the algorithm working. This is one of the most exhausting issues faced by machine learning professionals.
Over fitting of Training Data
Over fitting means a machine learning model trained along with a considerable amount of data adversely affecting its performance. It is like trying to fit into Oversized jeans. Unfortunately, this is one of the critical challenges of machine learning professionals. This defines the algorithm for training with noisy and biased data, which will affect its overall performance. Let’s understand this with the assistance of an example.
Let’s consider a model trained to distinguish between a cat, a rabbit, a dog, and a tiger.
The training data contains 100 cats, ten dogs, 1000 tigers, and 4000 Rabbits. Then there is a considerable probability that it will identify the cat as a rabbit. In this example, we had a massive amount of data, but it was biased; hence the prediction was adversely affected.
The problem can be tackled by –
- Analyze the data with the best level of perfection
- Using the data augmentation process
- Removing the outliers in the training set
- Selecting the model with minimum features
Conclusion
As machine learning evolve, the range of usage and applications of machine learning will also maximize. For effectively navigating the business issues in this new decade, it’s worth keeping an eye on how we can deploy challenges of machine learning applications across business domains to reduce costs, improve efficiency, and deliver better user experiences.
