

Introduction
In the field of machine learning, Hyperparameters play a crucial role in determining the performance of models. These parameters differ from the actual parameters of a model learned during training. Hyperparameters are set by the developer or data scientist and determine how the model learns and generalizes from the data.
What are Hyperparameters?
Hyperparameters are parameters not learned during the training process but set by the developer or data scientist before training begins. They control aspects of the learning process, such as the number of layers in a neural network, the learning rate of the optimizer, and the number of trees in a random forest model.
Many different hyperparameters can be adjusted, and finding the right combination of hyperparameters can be challenging and time-consuming. However, optimizing these hyperparameters can significantly improve the performance of a model.
Importance of Hyperparameters in Machine Learning
Hyperparameters are important because they determine how a model learns from the data and generalizes to new data. For example, the learning rate hyperparameter controls the step size of the optimizer during training. If the learning rate is too high, the model may overshoot the minimum of the loss function and fail to converge. Conversely, if the learning rate is too low, the model may converge slowly or get stuck in a suboptimal solution.
Similarly, the number of layers and nodes in a neural network determines its capacity and ability to learn complex patterns in the data. If the network is too small, it may underfit the data; if it is too large, it may overfit the data.
Types of Hyperparameters
There are many types of hyperparameters that can be adjusted to optimize machine learning models. Here are some common types of hyperparameters:
- Learning rate: This hyperparameter controls the step size of the optimizer during training. If the learning rate is too high, the model may overshoot the minimum of the loss function and fail to converge. If the learning rate increases, the model may converge slowly or get stuck in a suboptimal solution.
- The number of layers and nodes: The number of layers and nodes in a neural network determines its capacity and ability to learn complex patterns in the data. If the network is too small, it may underfit the data; if it is too large, it may overfit the data.
- Activation function: The activation function determines the output of each node in a neural network. Different activation functions can be used to introduce non-linearity into the model and improve its ability to learn complex patterns in the data.
- Regularization: Regularization techniques such as L1, L2, and dropout can be used to prevent overfitting by adding a penalty term to the loss function.
- Batch size: The batch size determines how many samples are used to calculate the gradient during each training iteration. Larger batch size can lead to faster convergence but may require more memory.
- Dropout rate: Dropout is a regularization technique that randomly drops out nodes during training to prevent overfitting. The dropout rate controls the probability that a node will be dropped out during training.
- Optimizer: The optimizer determines how the model updates its parameters during training. Different optimizers such as stochastic gradient descent (SGD), Adam, and RMSprop can be used to optimize the model.
- Number of trees: In ensemble methods such as random forests, the number of trees can be adjusted to improve the model’s performance.
Difference Between Parameters and Hyperparameters
In machine learning, parameters and hyperparameters are two variables that play different roles in the training and optimization of models.
- Parameters are variables that the model learns during the training process. These variables predict new data once the model has been trained. For example, in a linear regression model, the parameters would be the coefficients of the variables in the equation.
- Hyperparameters are variables set by the developer or data scientist before training begins. These variables determine how the model learns from the data and generalizes to new data. For example, hyperparameters in a neural network include the number of layers, the learning rate, and the batch size.
The main difference between parameters and hyperparameters is that parameters are learned by the model during training, while hyperparameters are set by the developer or data scientist before training begins. Parameters are specific to a given dataset and can vary depending on the data used to train the model. Hyperparameters, on the other hand, are independent of the data and determine how the model learns from the data.
What is a Model Parameter?
A model parameter is a variable that a machine learning model learns during the training process to make predictions or decisions. In other words, it’s a numerical value that represents some aspect of the relationship between the input data and the output data in a machine learning algorithm.
During the training process, the machine learning model tries to find the optimal values for the model parameters by adjusting them iteratively based on the error or loss function. The goal is to minimize the difference between the predicted output and the actual output.
For example, in a linear regression model, the model parameters are the slope and intercept of the line that best fits the input data. In a neural network, the model parameters are the weights and biases assigned to each node in the network.
Model parameters are an essential component of machine learning because they allow the model to generalize to new data and make accurate predictions. However, finding the right set of model parameters can be a challenging and time-consuming process, especially for complex models with a large number of parameters.
What is a Model Hyperparameter?
A model hyperparameter is a parameter that is set before the training process begins and is not learned by the model during training. Hyperparameters control the behavior of the training algorithm and can significantly affect the performance of the model.
Examples of hyperparameters include the learning rate, regularization strength, batch size, and the number of hidden layers in a neural network. The optimal values for these hyperparameters depend on the specific problem and dataset at hand, and finding the best combination can be a challenging process that requires experimentation and fine-tuning.
Hyperparameter tuning is a crucial step in the machine learning workflow and can have a significant impact on the model’s performance. Often, a hyperparameter search is conducted by training the model with different hyperparameter configurations and selecting the one that produces the best results on a validation set. Techniques such as grid search, random search, and Bayesian optimization are commonly used to automate this process and efficiently explore the hyperparameter space.
It’s essential to carefully choose and tune hyperparameters to obtain the best performance from a machine learning model. Choosing poorly performing hyperparameters can lead to overfitting, underfitting, or poor generalization to new data.
Optimizing Hyperparameters
Optimizing hyperparameters involves finding the best combination of hyperparameters that leads to the best performance of a model on a given task. This process can be time-consuming and requires experimentation and testing of different combinations of hyperparameters.

Several approaches to hyperparameter optimization include manual tuning, grid search, random search, and more advanced techniques such as Bayesian optimization and genetic algorithms.
Hyperparameter tuning is an important step in the machine-learning pipeline and can significantly improve the performance of models. However, finding the best combination of hyperparameters for a given task requires careful consideration and experimentation.
What is Hyperparameter Tuning?
Hyperparameter tuning, also known as hyperparameter optimization, is the process of selecting the optimal values for the hyperparameters of a machine learning model. Hyperparameters are variables the developer or data scientist sets before training begins and determine how the model learns from the data. Examples of hyperparameters include the learning rate, number of layers, and batch size.
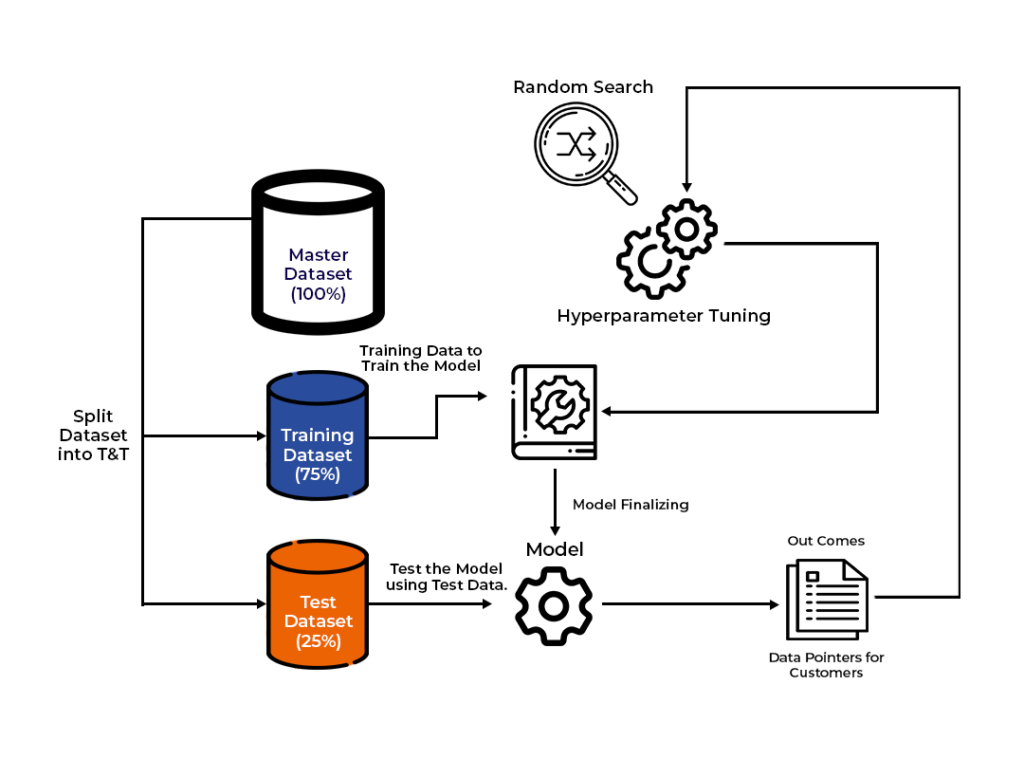
The goal of hyperparameter tuning is to find the best set of hyperparameters that will result in the highest performance of the model on the validation or test dataset. The process of hyperparameter tuning involves trying out different combinations of hyperparameters and evaluating the model’s performance using a chosen evaluation metric such as accuracy, precision, recall, or F1 score.
Steps to Perform Hyperparameter Tuning
Here are the steps to perform hyperparameter tuning:
- Identify the hyperparameters to be tuned. These can include learning rate, batch size, number of layers, regularization parameters, and others.
- There are different methods for hyperparameter tuning, including manual tuning, grid search, random search, and Bayesian optimization. Choose a search method based on the size of the search space and the computational resources available.
- Define a range of values to search over. For example, the learning rate could be searched over a range of [0.001, 0.01, 0.1, 1.0].
- Select an evaluation metric to assess the performance of the model for each set of hyperparameters. Common metrics include accuracy, precision, recall, F1 score, and mean squared error.
- Split the data into training, validation, and test sets. The training set is used to train the model, the validation set is used to select the best set of hyperparameters, and the test set is used to evaluate the final performance of the model.
- Train the model using the training set and evaluate its performance on the validation set for each set of hyperparameters.
- Choose the set of hyperparameters that yield the best performance on the validation set.
- Train a new model using the best hyperparameters on the combined training and validation sets, and evaluate its performance on the test set.
- If the performance of the model is not satisfactory, repeat the process with a different search space or search method, or try other techniques such as ensemble learning.
Conclusion
In summary, hyperparameters are parameters the developer or data scientist sets and determine how a model learns and generalizes from the data. Optimizing hyperparameters is an important step in the machine learning pipeline and can significantly improve the performance of models. However, finding the right combination of hyperparameters can be challenging and requires experimentation and careful consideration. As machine learning continues to grow and evolve, hyperparameter tuning will play a crucial role in developing high-performing models.
