

Introduction to Data Warehouse
In today’s data-driven age, a considerable amount of data gets generated daily from various sources such as emails, e-commerce websites, healthcare, supply chain and logistics, transaction systems, etc. It isn’t easy to store, maintain, and track such data as it grows exponentially as tie goes by and comes in different file formats such as text, parquet, CSV, etc. Due to various reasons, a data warehouse is required as it will analyze a massive amount of data and produce valuable data insights with data visualizations and reports.
What is big Query
When A data warehouse aggregates data from various sources into a central, consistent data repository to generate business insights and helps stakeholders in effective decision-making. Big Query is a serverless, fully managed, multi-cloud data warehouse Platform as a Service (PaaS) service given by Google Cloud Platform that assists in getting value-based business insights from big data. Big Query also provides a query engine for SQL to write SQL queries and has built-in machine-learning capabilities. We can use it for developing a highly scalable data warehouse using Google Big Query.
You may also like to read: A Complete Guide On Big Data Engineer
Data warehouse Working
A data warehouse aggregates data from multiple sources into a central, consistent data repository for generating business insights and assisting stakeholders in efficient decision-making. Data inside a data warehouse is loaded hourly, daily, or periodically from multiple applications and systems and does not change within that period. After that, data gets processed to be converted into an already existing data format in the data warehouse.
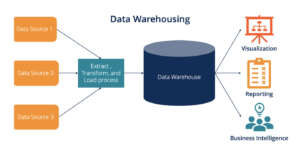
The processed data is stored in the data warehouses and later used by organizations for efficient decision-making. The data processing procedure is dependent on the data format. The data could be unstructured, semi-structured, or structured based on the source from that it is coming, such as transaction processing systems, healthcare, supply chain, etc. these aspects are essential when it comes to an understanding of Big Query data warehouse.
Big Query data warehouse is a Well-designed data warehouses for improving query performance and delivering high-quality data. Data warehouse enabling data integration and assisting in making more intelligent decisions using data mining, artificial intelligence, etc. Big query data warehouse that involves all the primary cloud service providers providing the data warehouse tools? Cloud-based data warehouse tools are highly scalable, provide disaster recovery, and are available on a pay-as-you-go basis. The cloud-based data warehouse tools are- Google Big Query, Amazon RedShift, Azure Synapse, Teradata, etc.
You may also like to read: A Guide on Data Architecture and Big data Architecture
Getting Started with Google Big Query
Big Query is a scalable, multi-cloud, distributed, fully managed, and server-less data warehouse Platform as Service (PaaS) given by Google Cloud Platform. Big Query is a primary repository that collects data from various sources such as Cloud Storage, Cloud SQL, Amazon S3, Azure Blob Storage, etc. Using federated queries, we can directly access the data from outside sources and analyze that data in Big Query without importing that data. Big Query also gives a query engine for SQL to write SQL queries and has built-in machine learning capability. We can develop a highly scalable data warehouse using Google Big Query. Big Query gives prescriptive and descriptive analysis, data storage to store data, and centralized data management and computer resources.
Data from multiple sources are stored inside table rows and columns in Capacitor columnar storage format inside Google Big Query storage, as the structure is optimized to perform analytical queries. Big Query gives full support for ACID transactions. Big Query ML provides geospatial analysis, business intelligence, machine learning, predictive analytics capability, ad-hoc analysis, etc. Tools such as Looker, Data Studio, etc., provide business intelligence supporting the Google Big Query.
Identifying and accessing management (IAM) is used for securing resources with the help of the access model. IAM provides data security and governance. Jobs run in Big Query to export, Query, copy, or load data are secured using roles that restrict the user or group from performing various activities. Storage is detached from the compute engine in Big Query, making it highly flexible to design the large-scale data warehouse.
Big Query Architecture
Big Query has a scalable, flexible, and serverless architecture, which could independently scale the storage and computing resources utilized in developing the data warehouse.
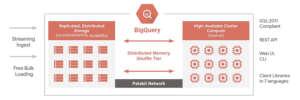
Big Query also gives a built-in engine for SQL, which improves query performance for extensive data and has built-in machine learning capability that helps stakeholders make smart decisions and design better marketing and promotional strategies. The features mentioned above of the Big Query architecture help the customers develop the data warehouse cost-effectively without worrying about infrastructure, security, database operations, and system engineering. Low-level infrastructure technologies offered by Google, such as Borg, Dremel, Colossus, and Jupiter, are internally being used by the Google Big Query architecture.
A large number of multi-tenant services are accompanied by low-level infrastructure technologies to give Scalability and flexibility to the Big Query architecture.
Colossus: Big Query uses Colossus for data storage usage. Colossus performs data recovery, replication, and distributed management operations to ensure data security.
Dremel: For performing computation operations internally, Big Query uses Dremel. Dremel is a multi-tenant cluster that converts SQL queries into execution trees to execute the queries.
Jupiter: Storage and computing resources use the Jupiter network for communication.
Borg: Borg does orchestration to perform automated configuration, management, and coordination between services in Big Query.
Advantages of using Google Big Query
Here are some advantages of using Google Big Query
- Advanced Business Intelligence Capabilities: Using Big Query, we can integrate data from multiple sources. It can easily manage data of various formats from all sources in Big Query, whether it is some external data source or services present inside GCP. Then this data is processed, formatted, and subsequently used by organizations for effective decision-making by expanding business intelligence capabilities.
- Data consistency and improved data quality: data from multiple sources is stored inside rows and columns of the table in the format of the Capacitor columnar. Storage format after data compression using the compression algorithm in Google Big Query storage since this format is optimized for performing analytical queries. A large request provides full support for ACID transactions. Compressed data takes up less space. Thus, Big Query delivers improved data quality and consistency using data compression and a column-based data storage format.
- Scalability and real-time performance: Using federated queries, we can directly access data from external sources and analyze this data in an essential question without importing this data. In addition, the volume or number of data sources can be increased or decreased. In addition, Big Query Omni allows you to analyze data stored in Amazon S3 or Azure blob storage, with the flexibility to replicate data when needed. All of this increases the performance and Scalability of the data warehouse in real time.
- Security: Identity and Access Management (IAM) is used to protect resources using an access model. IAM ensures data security and management. Tasks performed in Big Query for exporting, querying, copying, or uploading roles protect data because roles restrict a user or group from performing various actions. Thus, a secure data warehouse is being developed using identity and access management and functions in Big Query.
- Disaster recovery and fault tolerance: Data stored in a large query is replicated in different regions. In undesirable circumstances, data can be quickly recovered using the Recovery Time Target (RTO) and the Recovery Point Target (RPO). The data in Big Query is highly consistent, durable, easy to recover, and has better fault tolerance and a disaster recovery mechanism.
Case Scenarios for using Big Query
Below are some scenarios in which you can use Google Big Query:
- Recommendation System for e-commerce: Google Big Query is used to develop a recommendation system for e-commerce. Customer feedback data can generate product recommendations using Big Query artificial intelligence, machine learning, and predictive analytics capabilities. In addition, with the help of Vertex AI, it is possible to predict the life expectancy of a customer, the nature of purchases, etc., which can help e-commerce organizations plan their advertising and marketing strategies.
- Data Warehouse Migration: To speed up real-time data analysis, organizations may prefer to migrate their existing data warehouses to Google Big Query. Other data stores, such as Snowflake, Redshift, Teradata, etc., can be migrated to Big Query to increase security and Scalability.
Conclusion
Now that we have learned what big Query is and what big query data warehouse is, to create a data warehouse for an ecommerce scenario using Google Big Query. We have understood how data warehouses built using Big Query are cost-effective, secure, and easily scalable. We learned how we could create a data warehouse using Big Query for a real-time scenario. The following are the main conclusions from the above guide :
- We have gained a good understanding of the data warehouse and the scenarios in which a data warehouse is required.
- We have also seen how data types from various sources are collected and analyzed in the data warehouse.
- We understood how data is stored and maintained, ML algorithms are used, and security is maintained in Big Query.
- We’ve looked at the features, the underlying architecture, the use cases, and the benefits of using Big Query.
